Image Retrieval[]
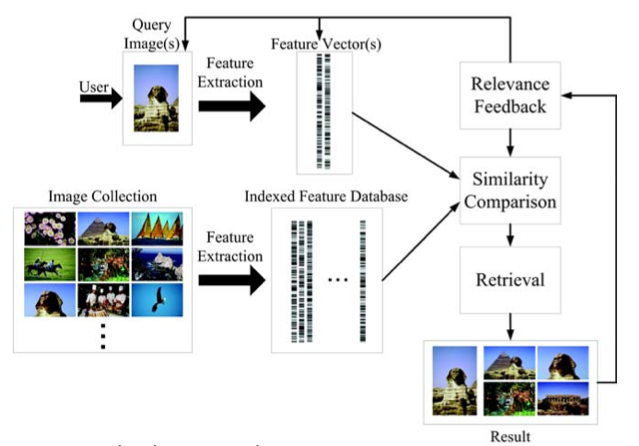
Currently there are two main techniques for image retrieval: text-based and content-based. Text-based image retrieval uses manual annotation of images and text-based search to find images matching the query. Content-based image retrieval (CBIR) uses automatic extraction of low-level image features such as color, shape, texture etc. A query is then solved by using an example image, sketch or color.
Both approaches have known drawbacks, and as there are huge amount of images available, a more efficient image retrieval technique is needed. The drawbacks with text-based image retrieval is that manual annotation are time consuming and that users have different semantic views, concepts and languages. One drawback with CBIR is that it is usually very imprecise, but it is useful within domains such as fingerprint recognition, medical imaging and face recognition.
{kind=link}
Content-based image retrieval system
Image features that can be used in CBIR are; primitive features, such as mean color and color histogram; semantic features, such as color layout and texture; domain specific features, such as face/fingerprint recognition. A distance between two objects can be measured based on features, which can be used when processing a query by setting the allowed distance between the query and the result object.
Histogram[]
Histograms can be used to search through images. Two images can be said to be similar if their histogram are similar. To match histograms, the histogram for each image is stored and compared using some statistical method. A sorted match, with the best fit first, is returned. Histogram are not well suited to say anything about the shapes appearing in the picture, they only say something about the colors in the image and their distribution in the image.
To match shapes, it is easiest if the background is plain, as this makes it easier to find a vector that describes the outline of the object. This vector must, however, also be invariant to scale, position and rotation.
Context-Aware Image Management (CAIM)[]
CAIM is a new approach trying to take advantage of the image context when solving a query. It tries to collect and combine image context information from multiple sources, and combines techniques from context-based image retrieval with traditional image retrieval techniques.
The capture context of an image can be the environment in which it was taken, information such as date, location, height, sensor data (e.g. temperature), information about nearby objects etc. The usage context of an image is where the image is used (e.g. collection, document), and may also include textual description of a collection, a document abstract, keywords describing the collection or document and text surrounding the image.